召回测试
召回测试是基于给定的查询文本,测试知识库的召回效果。通过实际输入业务中会出现的查询语句,可以直观看到哪些文档切片被命中、命中的相似度得分是多少,从而判断当前的分段策略、检索模式、参数配置是否合理,并针对性地进行调整。
在知识库编辑配置页面点击召回测试,进入测试页面。
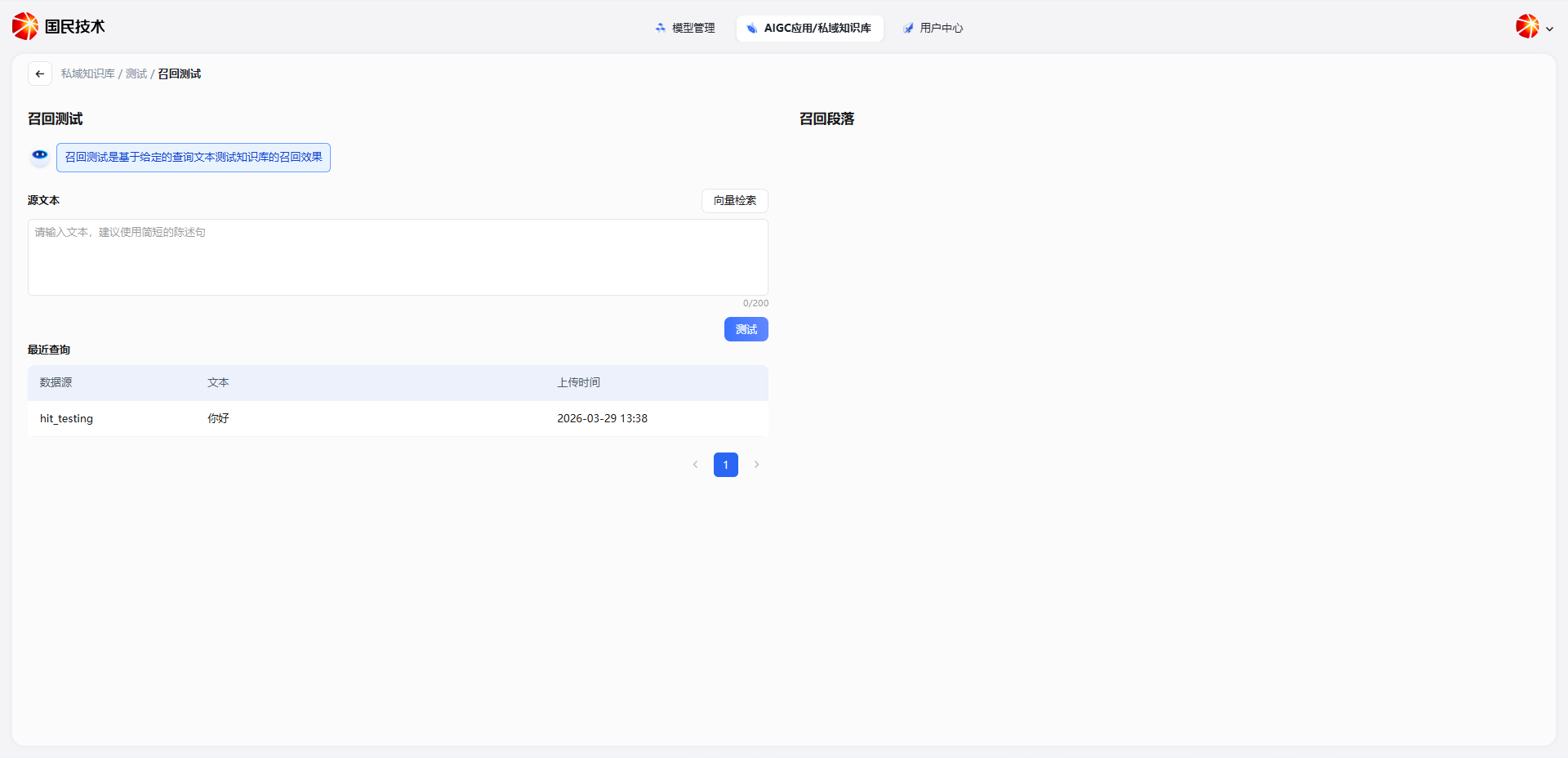
执行测试
在左侧源文本输入框中输入查询内容(建议使用简短的陈述句,最多 200 字),点击测试按钮,系统将按照当前检索设置执行一次召回,右侧召回段落区域展示命中的文档切片。
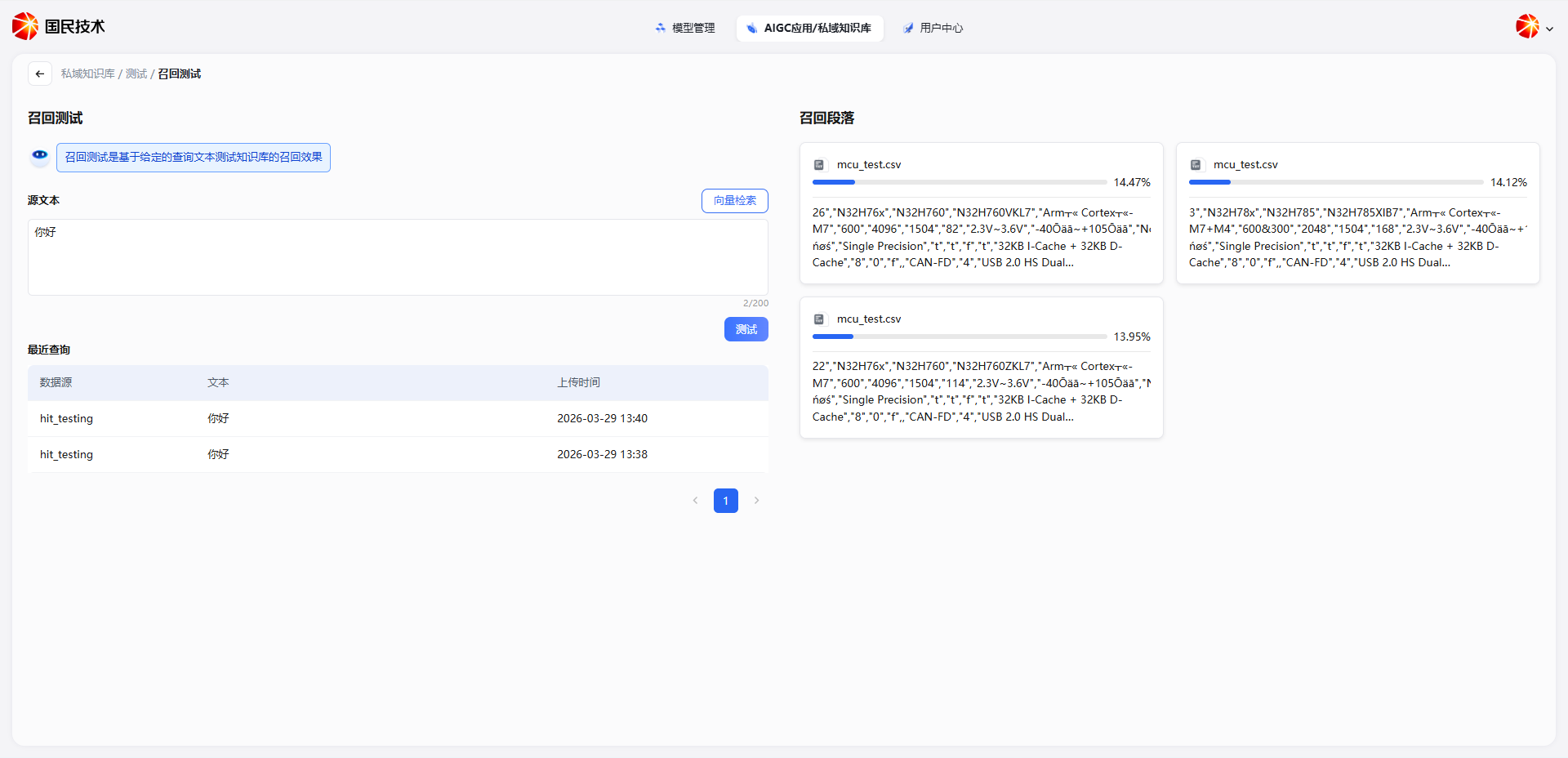
每条召回结果包含以下信息:
| 字段 | 说明 |
|---|---|
| 来源文件 | 该切片所属的原始文档名称 |
| 相似度得分 | 该切片与查询内容的匹配程度,以百分比显示,分值越高越相关 |
| 切片内容 | 命中的文档片段原文预览 |
页面下方的最近查询记录了历史测试的数据源、查询文本及时间,方便对比不同参数调整前后的效果变化。
通过召回测试调整参数
召回测试的核心价值在于帮助发现检索问题并指导参数优化,常见场景如下:
命中内容不相关 / 得分普遍偏低
- 说明当前分段粒度过大,切片包含过多无关内容,建议减小最大分段长度后重新处理文档
- 或切换检索模式,从向量检索改为混合检索,结合关键词匹配提升精度
应该命中的内容没有出现
- 检查 Score 阈值是否设置过高,导致相关切片被过滤,可适当降低阈值
- 检查 Top K 是否过小,增大返回数量后再测试
- 若查询词为产品型号、文件编号等精确词,建议开启索引增强,通过元数据直接定位
返回切片过多且质量参差不齐
- 适当提高 Score 阈值,过滤低相关度的切片
- 减小 Top K 值,只保留最相关的若干条结果
语义理解效果差(近义词、同义表达无法命中)
- 切换为向量检索或混合检索模式,向量检索对语义相似度的理解更强
- 检查当前 Embedding 模型是否适合中文语料,必要时在知识库设置中更换模型
设置检索方式
点击源文本输入框右上角的向量检索按钮,可在测试页面临时切换检索方式,无需修改知识库设置即可对比不同模式的召回效果。
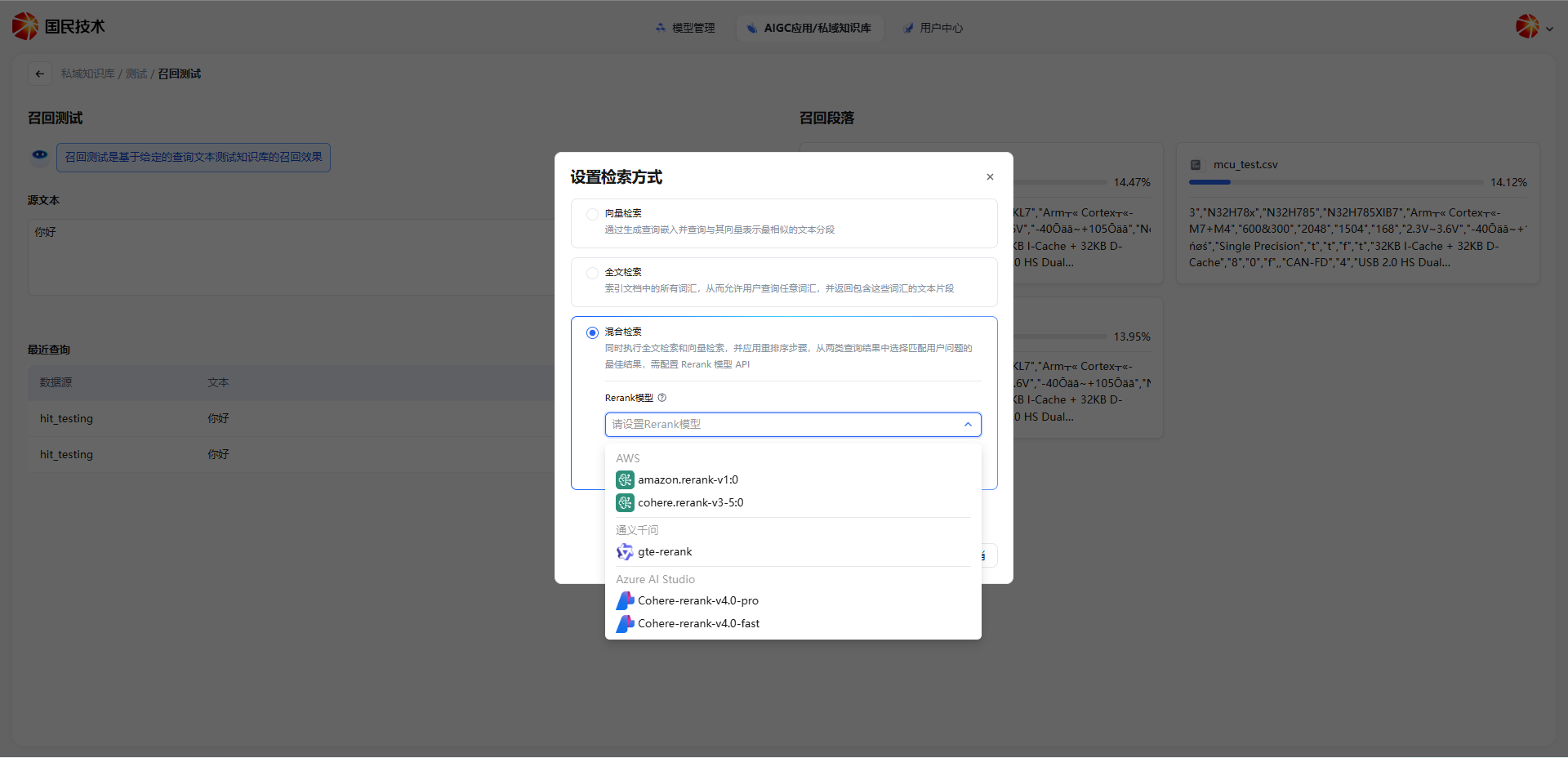
支持以下三种检索方式:
| 检索方式 | 说明 |
|---|---|
| 向量检索 | 通过生成查询嵌入,查找与其语义最相似的文本分段,适合自然语言问答 |
| 全文检索 | 索引文档中的所有词汇,允许查询任意词汇并返回包含这些词汇的文本片段,适合精确关键词匹配 |
| 混合检索 | 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选取最匹配的内容,需配置 Rerank 模型 |
选择混合检索时,需在下方选择 Rerank 模型(如 gte-rerank、Cohere-rerank-v4.0-pro 等),Rerank 模型会对初步召回的结果进行二次精排,将最相关的切片排在前面,显著提升最终返回内容的质量。
提示: 在召回测试中切换检索方式仅影响本次测试,不会修改知识库的实际检索配置。如需永久生效,请前往知识库配置 - 检索设置中保存。