代码运行节点
概述
代码运行节点支持在工作流中直接执行 Python 或 NodeJS 代码,用于实现自定义的数据处理逻辑。相比其他节点,代码节点提供了更高的灵活性,适合处理复杂的数据转换、计算或格式化任务,无需依赖外部服务。
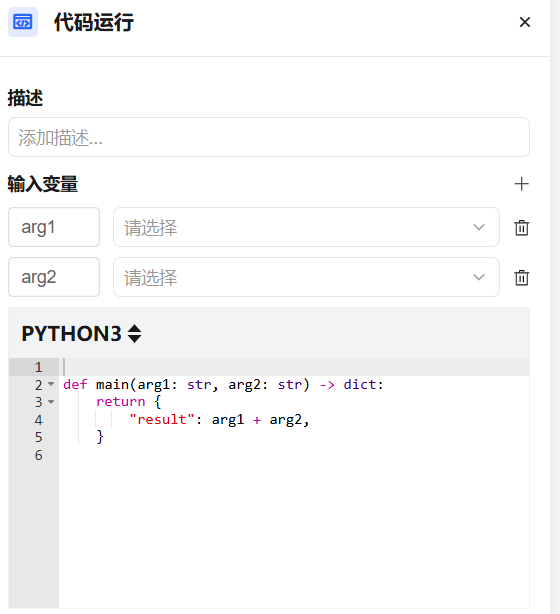
支持的运行环境
| 运行时 | 说明 |
|---|---|
Python 3 | 适合数据处理、数学计算、文本操作等场景 |
NodeJS | 适合 JSON 处理、字符串操作、异步逻辑等场景 |
配置项说明
| 配置项 | 说明 |
|---|---|
| 运行时 | 选择代码执行环境,支持 Python 3 / NodeJS |
| 输入变量 | 从上游节点引用的变量,作为代码的输入参数。支持下拉搜索,可在输入框中输入关键词快速筛选并选择目标变量 |
| 代码编辑器 | 编写自定义处理逻辑,需包含 main 函数作为入口 |
| 输出变量 | 定义代码执行后返回的字段名称与类型 |
代码入口规范
代码节点要求以 main 函数作为执行入口,输入变量以参数形式传入,返回值须为字典(Python)或对象(NodeJS)。
Python 示例:
python
def main(input_text: str) -> dict:
result = input_text.strip().upper()
return {
"output": result,
"length": len(result)
}NodeJS 示例:
javascript
async function main({ inputText }) {
const result = inputText.trim().toUpperCase();
return {
output: result,
length: result.length
};
}典型使用场景
场景一:数值计算(Arithmetic)
对上游节点传入的数值进行加减乘除、取模、幂运算等数学处理,并将结果传递给下游节点。
python
def main(price: float, quantity: int, discount: float) -> dict:
subtotal = price * quantity
total = subtotal * (1 - discount)
return {
"subtotal": subtotal,
"total": round(total, 2)
}场景二:JSON 转换(JSON Transform)
对结构复杂的 JSON 数据进行字段提取、重组或格式标准化,便于后续节点直接使用。
python
import json
def main(raw_json: str) -> dict:
data = json.loads(raw_json)
return {
"name": data.get("user", {}).get("name", ""),
"email": data.get("user", {}).get("contact", {}).get("email", ""),
"is_active": data.get("status") == "active"
}场景三:文本处理(Text Processing)
对字符串进行清洗、分割、拼接、正则匹配等操作,适用于格式化输出或关键词提取。
python
import re
def main(raw_text: str) -> dict:
cleaned = re.sub(r'\s+', ' ', raw_text).strip()
words = cleaned.split(' ')
return {
"cleaned_text": cleaned,
"word_count": len(words),
"preview": cleaned[:100]
}场景四:日期与时间格式化
将时间戳或非标准日期字符串转换为统一格式,供报告生成或条件判断使用。
python
from datetime import datetime
def main(timestamp: int) -> dict:
dt = datetime.fromtimestamp(timestamp / 1000)
return {
"formatted": dt.strftime("%Y-%m-%d %H:%M:%S"),
"date_only": dt.strftime("%Y-%m-%d"),
"year": dt.year
}安全策略
执行环境隔离
代码节点运行在沙箱环境中,每次执行均为独立进程,执行完毕后自动销毁,不保留任何运行状态。
禁止访问的能力
出于安全考虑,代码节点对以下能力进行了限制:
| 限制项 | 说明 |
|---|---|
| 文件系统访问 | 不允许读写本地文件,防止数据泄露 |
| 网络请求 | 不允许在代码中发起 HTTP/TCP 等网络调用,如需请求外部接口请使用 HTTP 请求节点 |
| 系统命令执行 | 禁止调用 os.system、subprocess 等系统级命令 |
| 动态代码执行 | 禁止使用 eval、exec 等动态执行函数 |
| 无限循环 | 执行超时将被强制终止,防止资源耗尽 |
执行限制
| 限制项 | 限制值 |
|---|---|
| 最大执行时长 | 10 秒 |
| 最大内存占用 | 256 MB |
| 输入数据大小 | 单个变量不超过 1 MB |
依赖库说明
代码节点内置了常用标准库,不支持安装第三方包。可用库包括:
- Python:
json、re、math、datetime、hashlib、base64、collections、itertools等标准库 - NodeJS:
crypto、path、url、querystring、Buffer等内置模块
输出变量配置
代码执行完成后,返回值中的字段需在「输出变量」中预先声明,才能被下游节点引用。
| 字段类型 | 说明 |
|---|---|
String | 字符串 |
Number | 数值(整数或浮点数) |
Boolean | 布尔值 |
Object | JSON 对象 |
Array | 数组 |
若代码返回了未声明的字段,该字段将被忽略,不会传递给下游节点。
高级功能
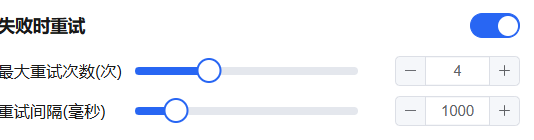
错误重试
代码节点支持在执行失败时自动重试,适用于偶发性运行时错误。
- 最大重试次数:10 次
- 最大重试间隔:5000 ms
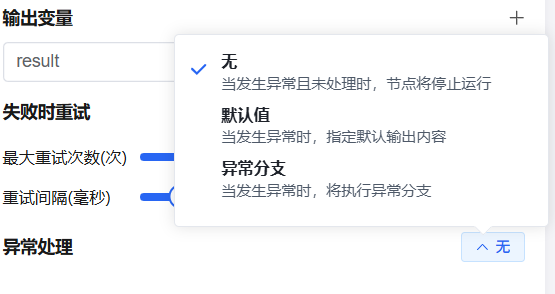
异常处理
当代码执行抛出未捕获异常时,可通过配置异常分支执行降级逻辑,避免中断整个工作流。
配置步骤:
- 在代码节点中启用「异常处理」开关
- 选择异常处理方案(如返回默认值、跳转至指定节点)并完成配置
常见问题
Q:代码执行超时怎么办?
检查是否存在大数据量循环或低效算法。建议对大列表使用生成器,避免一次性加载全量数据。若数据量确实较大,可考虑在上游节点先做过滤或分页处理。
Q:输出变量未被下游节点识别?
确认以下两点:
main函数的返回值是字典/对象类型,且字段名与输出变量声明一致- 输出变量面板中已添加对应字段并选择了正确的数据类型
Q:能否在代码中调用其他节点的能力?
不支持。代码节点仅用于纯计算逻辑,与外部服务的交互(如 HTTP 请求、数据库查询)需通过对应的专用节点实现,并通过变量传递数据。
Q:Python 和 NodeJS 如何选择?
- 数学计算、正则处理、数据结构操作优先选 Python
- JSON 操作、字符串模板、异步逻辑优先选 NodeJS
- 两者能力相近时,选择团队更熟悉的语言即可