模型
定义
调用大语言模型的能力,处理用户在 “开始” 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息 
应用场景
LLM 节点是 Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力, 根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
意图识别, 在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
文本生成, 在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
内容分类, 在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
文本转换, 在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
代码生成, 在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
RAG, 在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
图片理解, 使用具备视觉能力的LLM,理解与问答图像内的信息。
文件分析, 在文件处理场景中,使用LLM识别并分析文件包含的信息。
选择合适的模型,编写提示词,你可以在 Workflow 中构建出强大、可靠的解决方案。
配置示例
在画布页面编辑,点击鼠标右键或轻点上一节点末尾的 + 号,添加节点并选择模型。
- 选择模型, 包括 Azure OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、Vertex AI 的 Gemini 系列等,选择一个模型取决于其推理能力、成本、响应速度、上下文窗口等因素,你需要根据场景需求和任务类型选择合适的模型。
- 配置模型参数, 模型参数用于控制模型的生成结果,例如温度、TopP,最大标记、回复格式等,为了方便选择系统同时提供了 3 套预设参数:创意,平衡和精确。如果你对以上参数并不熟悉,建议选择默认设置。若希望应用具备图片分析能力,请选择具备视觉能力的模型。
- 填写上下文(可选), 上下文可以理解为向 LLM 提供的背景信息,常用于填写知识库检索的输出变量。
- 编写提示词, LLM 节点提供了一个易用的提示词编排页面,选择聊天模型或补全模型,会显示不同的提示词编排结构。如果选择聊天模型(Chat model),你可以自定义系统提示词(SYSTEM)/用户(USER)两部分内容。

在提示词编辑器中,你可以通过输入 / 呼出 变量插入菜单,将 上游节点变量 插入到提示词中作为上下文内容。 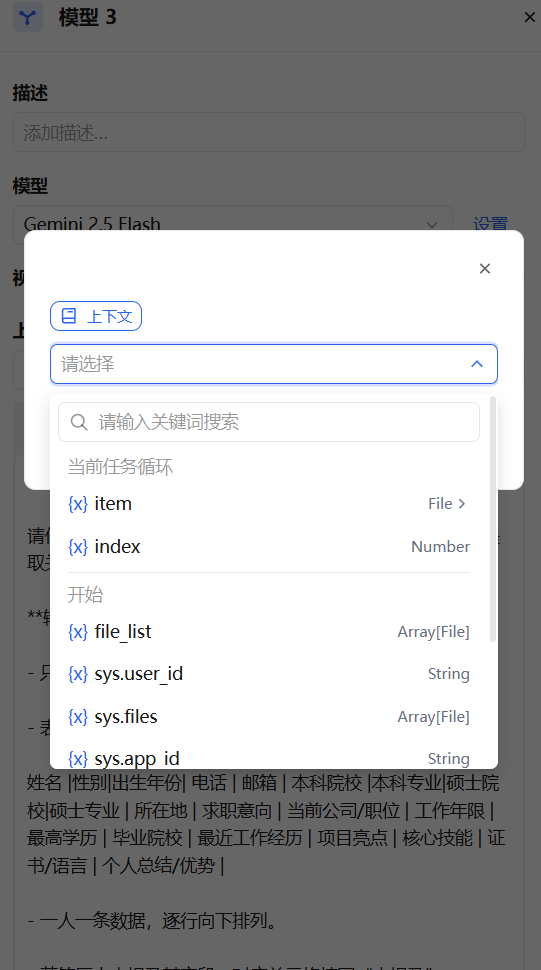
特殊变量说明
上下文变量
上下文变量是为知识库检索场景设计的特殊变量类型,仅可在 LLM 节点内引用。当 LLM 节点的提示词中引用了知识库节点的输出时,该输出会以"上下文变量"的形式传入。
- 上下文变量的值是一个结构化的文本片段列表,包含从知识库中检索到的相关内容。
- 在提示词中通过
上下文引用。 - LLM 会将这些检索结果作为背景知识来回答用户问题,实现 RAG(检索增强生成)效果。
图片变量
图片变量用于向支持视觉能力的 LLM(如 GPT-4V、Claude 3 等多模态模型)传入图片内容。
- 支持传入图片 URL 或 Base64 编码的图片数据。
- 图片变量通常来源于"文件上传"节点或用户输入中的图片类型变量。
- 在提示词中引用图片变量后,LLM 可以对图片内容进行理解、描述或分析。
- 仅在模型有视觉能力时有效。
文件变量
文件变量用于将文件内容(如 PDF、Word、TXT 等)传递给 LLM 节点进行处理。
- 文件变量通常来源于"文件上传"节点或工作流的文件类型输入变量。
- 支持多种文件格式,具体支持范围取决于开始节点支持上传的文档类型范围。
- 适用于文档问答、文档摘要、内容提取等场景。
高级设置
错误重试: 针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
最大重试次数为 10 次
最大重试间隔时间为 5000 ms
异常处理: 提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务