文档拆分
定义
文档拆分节点是长文本处理流程中的核心分段工具,用于将上游「文本提取」节点输出的结构化长文本,按照指定的 Token 长度自动切割为多个语义完整的短段落,以适配大模型上下文窗口限制、向量库入库要求等下游场景,确保内容可被高效处理与调用。
使用场景
| 场景 | 说明 |
|---|---|
| 知识库构建 | 将长文档拆分为适配向量库的片段,用于相似度检索 |
| 大模型问答 | 拆分超长上下文,避免模型因 Token 超限导致回答截断或失败 |
| 内容分发 | 将大段内容拆分为适合阅读的短段落,用于推送、摘要生成等场景 |
配置使用
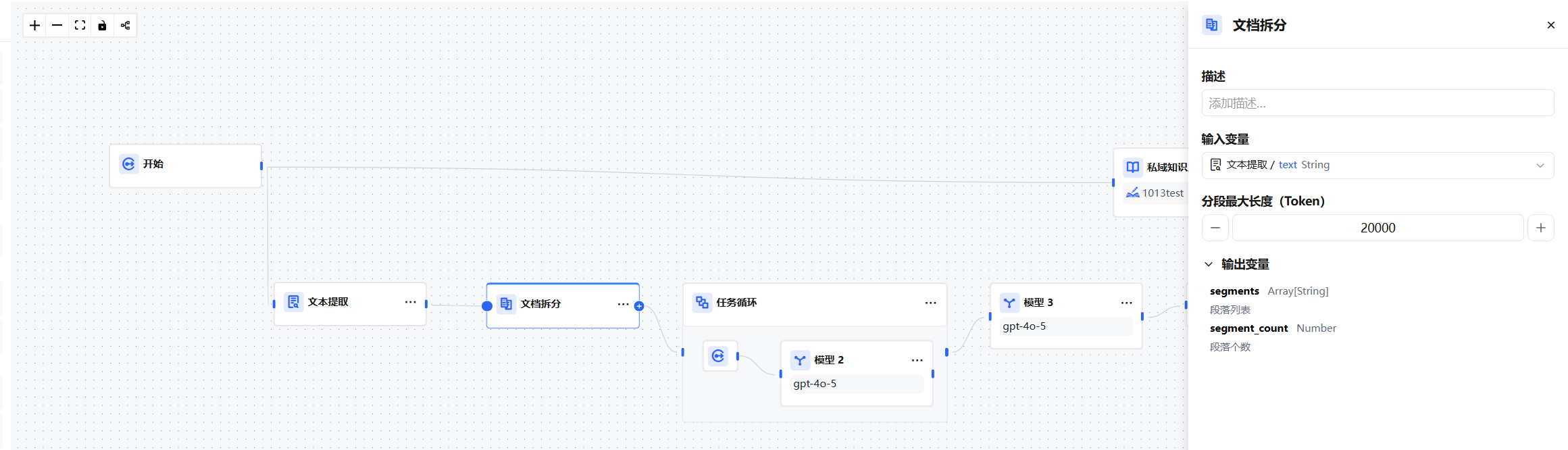
输入配置
- 输入变量:连接上游「文本提取」节点,选择其输出的文本变量作为输入。
- 分段最大长度(Token):每个段落的最大 Token 数,默认值为
500,可根据实际文本大小和下游需求调整。
输出变量
| 变量名 | 类型 | 说明 |
|---|---|---|
segmentsArray | Array[String] | 拆分后的段落列表 |
segment_count | Number | 段落总数 |
下游使用
文档拆分节点输出的是数组类型变量,通常需要配合任务循环节点对每个段落逐一处理。
典型流程:
文本提取节点 → 文档拆分节点 → 任务循环节点
└─ 模型节点(处理单个段落)
→ 整合输出节点在任务循环节点中,将循环输入设置为文档拆分节点输出的 segmentsArray,循环体内的节点即可通过循环变量引用当前段落内容,传入模型节点进行翻译、摘要、问答等处理,所有轮次结果最终汇总为数组输出。
segment_count可用于在后续节点中做条件判断,例如当段落数超过阈值时走不同的处理分支。