参数提炼节点
定义
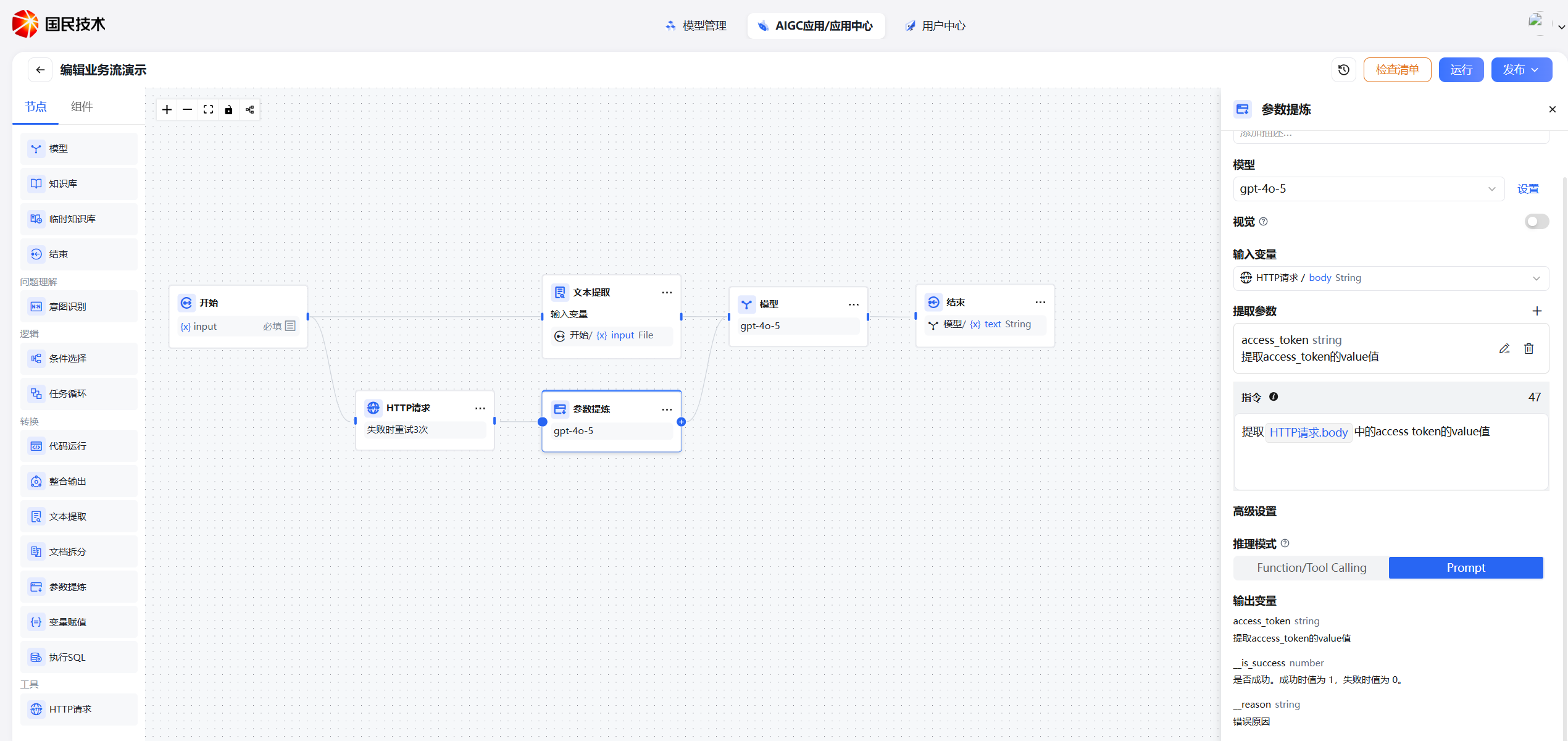
参数提炼节点利用 LLM 从自然语言中推理并提取结构化参数,将用户的非结构化输入转换为工具调用、HTTP 请求或下游节点所需的标准化数据格式。
配置说明
基础配置
| 配置项 | 说明 |
|---|---|
| 模型 | 选择用于推理提取的 LLM,推荐使用理解能力较强的模型以提升提取准确率 |
| 输入变量 | 作为提取来源的文本,通常为用户输入或上游节点的输出,输入变量支持 file |
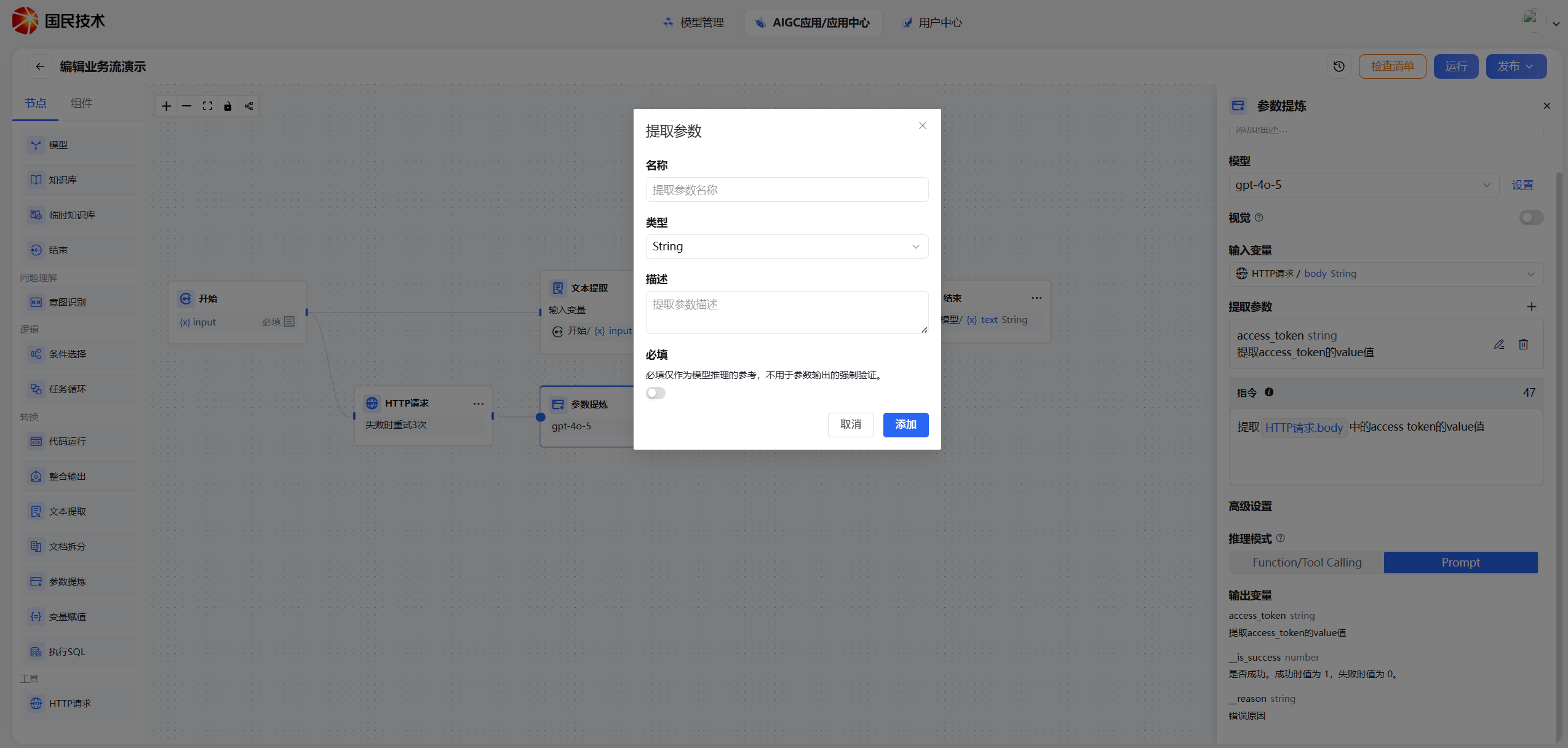
| 提取参数 | 提取参数需要手动添加参数类型,详见下方参数定义 |
| 推理模式 | 控制模型提取参数的方式,详见下方说明 |
| 参数列表 | 定义需要提取的参数名称、类型及描述 |
| 指令(可选) | 补充说明提取规则或特殊要求,帮助模型更准确地理解提取意图 |
参数定义
每个参数需配置以下字段:
| 字段 | 说明 |
|---|---|
| 参数名 | 提取后的变量名,供下游节点引用 |
| 参数类型 | 支持 String、Number、Boolean、Array、Object |
| 描述 | 对该参数含义的说明,描述越清晰,模型提取越准确 |
| 是否必填 | 标记为必填时,若模型无法提取该参数,节点将返回异常 |
记忆
开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
开启记忆,记忆窗口默认 50 轮
推理模式
参数提炼节点提供两种推理模式,适用于不同场景:
函数调用模式(Function/Tool Calling)
利用模型原生的 Function/Tool Calling 能力,将参数定义转换为工具描述,由模型直接输出结构化 JSON。
- 优点:输出格式稳定,解析可靠
- 适用:支持 Function/Tool Calling 的模型(如 GPT-4、Claude 等)
提示词推理模式(Prompt)
通过构造提示词引导模型以文本形式输出参数,再由系统解析为结构化数据。
- 优点:兼容不支持 Function/Tool Calling 的模型
- 适用:开源模型或能力受限的模型
推荐优先使用函数调用模式,输出更稳定。若所选模型不支持,系统将自动降级为提示词推理模式。
输出变量
参数提炼节点执行完成后,每个已定义的参数均作为独立变量输出,可在下游节点中直接引用。
例如定义了以下参数:
| 参数名 | 类型 | 示例值 |
|---|---|---|
city | String | "北京" |
date | String | "2026-03-24" |
adult_count | Number | 2 |
下游节点可通过 参数提炼节点.city、参数提炼节点.date 等方式引用对应值。
典型使用场景
场景一:为工具调用提取入参
工作流内的工具节点通常要求结构化输入。用户以自然语言描述需求时,参数提炼节点可自动识别并提取工具所需的各项参数,无需用户手动填写表单。
示例: 用户输入「帮我查一下北京后天的天气」,参数提炼节点从中提取:
city→北京date→2026-03-26
提取结果直接传入天气查询工具节点。
场景二:为 HTTP 请求提取 Token 及动态参数
调用需要鉴权的 HTTP 接口时,Token 或其他认证信息可能包含在用户输入、上下文变量或前置节点的响应中。参数提炼节点可从这些来源中精准提取 Token 及业务参数,再传入 HTTP 请求节点的请求头或请求体。
示例: 上游节点返回如下文本:
Authorization: Bearer eyJhbGciOiJIUzI1NiJ9.xxx
用户ID: 10086
操作: 查询账单配置参数提炼节点提取:
| 参数名 | 类型 | 描述 |
|---|---|---|
token | String | Bearer Token,用于接口鉴权 |
user_id | String | 用户唯一标识 |
action | String | 用户请求的操作类型 |
提取结果传入 HTTP 请求节点,token 填入 Authorization 请求头,user_id 和 action 填入请求体。
场景三:将自然语言转换为数组供迭代节点使用
迭代节点要求输入为数组格式。当用户以自然语言列举多个对象时(如「帮我翻译这三段话:…」),参数提炼节点可将其识别并提取为数组,直接传入任务循环节点进行批量处理。
示例: 用户输入「请分别总结以下三篇文章:[文章A]、[文章B]、[文章C]」,提取参数:
| 参数名 | 类型 | 描述 |
|---|---|---|
articles | Array | 需要总结的文章列表 |
提取结果 ["文章A内容", "文章B内容", "文章C内容"] 直接传入任务循环节点。
高级功能
提取准确率优化建议
- 参数描述要具体:描述中说明参数的格式、单位或示例值,模型提取更准确
- 合理标记必填项:仅将核心参数标为必填,可选参数允许为空,减少不必要的异常
- 补充指令约束边界:在指令中说明特殊规则,如「日期统一转换为 YYYY-MM-DD 格式」
- 选择合适的模型:复杂提取任务优先选用推理能力更强的模型