文本提取
定义
LLM 自身无法直接读取或解释文档的内容。因此需要将用户上传的文档,通过文档提取器节点解析并读取文档文件中的信息,转化文本之后再将内容传给 LLM 以实现对于文件内容的处理。
应用场景
构建能够与文件进行互动的 LLM 应用,例如 ChatPDF 或 ChatWord;
分析并检查用户上传的文件内容;
节点功能
文档提取器节点可以理解为一个信息处理中心,通过识别并读取输入变量中的文件,提取信息后并转化为 string 类型输出变量,供下游节点调用。
文档提取器节点结构分为输入变量、文档解析服务、图片解析、拆页提取、输出变量。 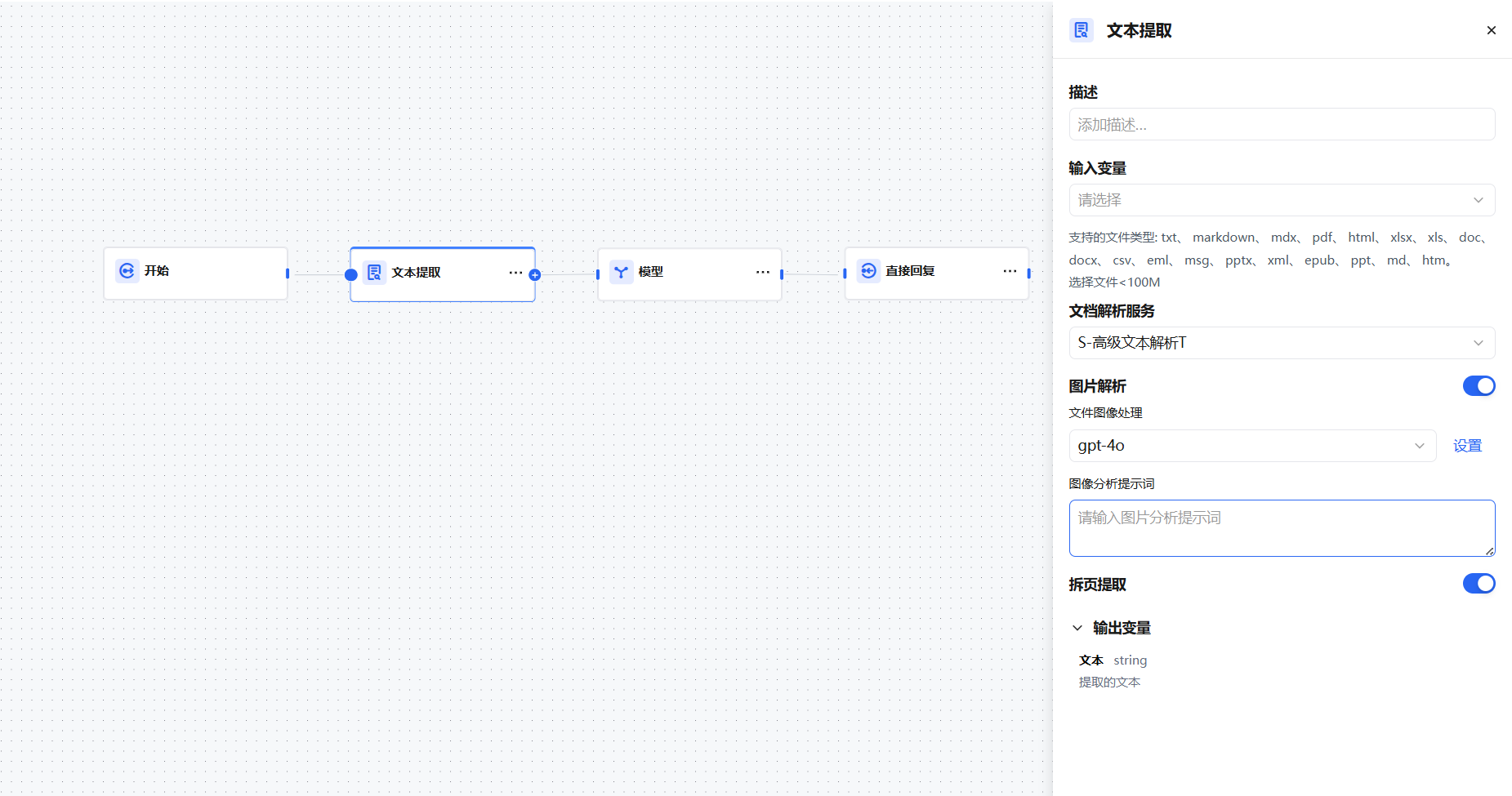
输入变量
文档提取器仅接受以下数据结构的变量:
File,单独一个文件Array[File],多个文件
文档提取器仅能够提取文档类型文件中的信息,例如 TXT、Markdown、PDF、HTML、DOCX 格式文件的内容,无法处理图片、音频、视频等格式文件,选择文件需要小于 100M 。
文档解析服务
默认展示模型管理-模型配置页面上选择的文档解析服务选项,文档解析服务功能:把文本转换为 Markdown 格式,保留文档的标题层级、表格、列表等结构信息,便于下游节点对内容进行结构化处理。
支持以下两种解析方式:
默认解析:使用系统内置的文档解析引擎,适用于格式规范的 TXT、Markdown、HTML、DOCX 等文档,解析速度快,无需额外配置。
自定义解析服务:在模型管理-模型配置页面配置第三方文档解析服务(如 azure_document_intelligence、deepseek等),适用于复杂排版的 PDF 或含有大量表格、图表的文档,解析精度更高。
图片解析
图片解析功能用于提取上传文档中嵌入的图片内容,将图片信息转化为文字描述后合并至文档文本输出,使 LLM 能够理解文档中的图表、截图等视觉信息。
开启图片解析后,需配置以下两项参数:
文件图像处理模型:选择具备图像识别能力的多模态推理模型(如 GPT-4o、Claude 3 等),用于解析文档中嵌入图片的内容。可通过调整模型参数(如 temperature、max_tokens)来控制图像描述的详细程度与准确性。
图像分析提示词:为图像处理模型编写专属提示词,引导模型按照预期方式描述图片内容。例如,针对流程图可提示"请详细描述图中的流程步骤和节点关系",针对数据图表可提示"请提取图中的数据指标和趋势信息"。
拆页提取
当只需要提取文件中某一页码区间的内容时,可开启拆页提取功能,避免处理无关内容造成资源浪费。
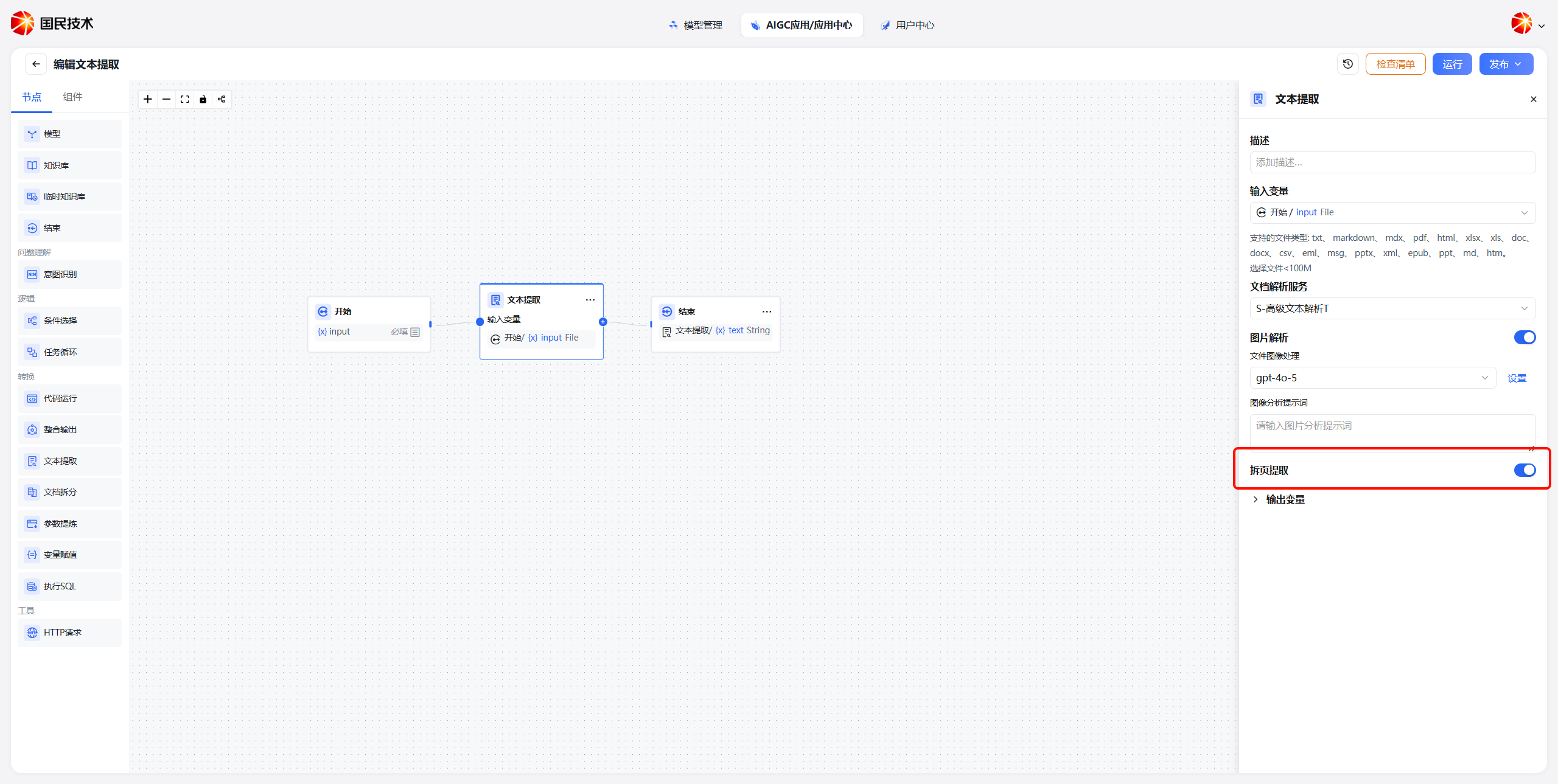
开启后,上传文件时可点击预览查看文件内容,确定目标页码范围后填入起止页数。
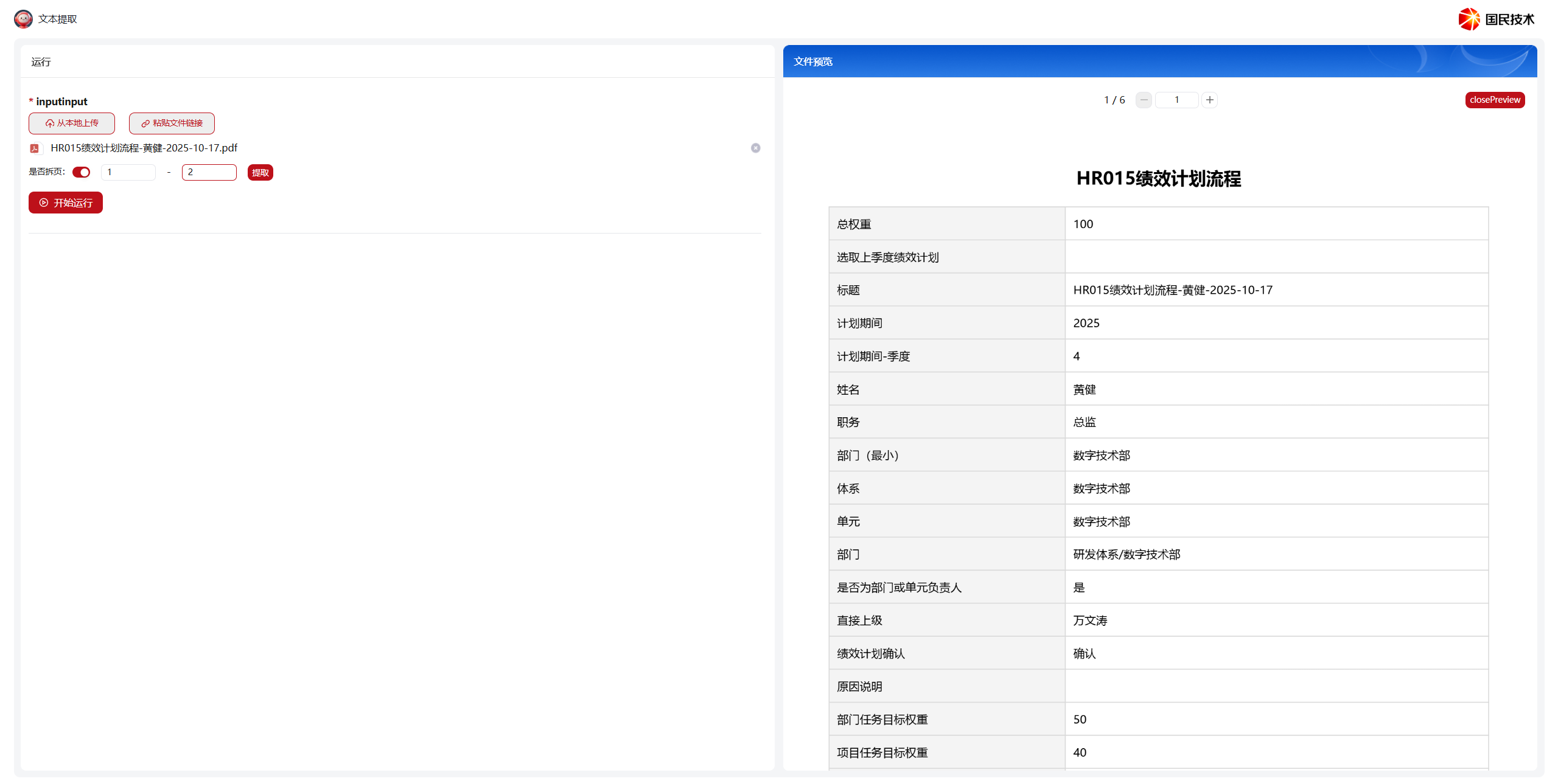
点击提取后节点将仅处理指定范围内的页面内容。
输出变量
输出变量固定命名为 text。输出的变量类型取决于输入变量:
输入变量为
File,输出变量为string输入变量为
Array[File],输出变量为array[string]
Array 数组变量一般需配合列表操作节点使用