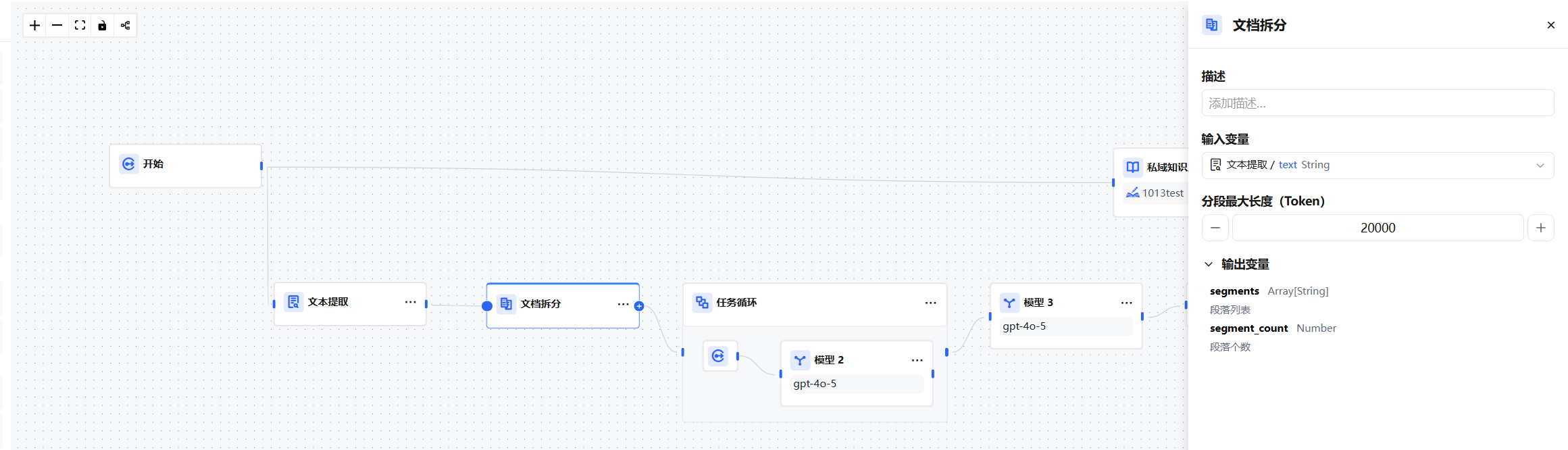
Document Split Node
Definition
The Document Split node is the core segmentation tool for long-text processing pipelines. It takes the structured long text output from an upstream Text Extraction node and automatically splits it into multiple semantically complete short segments based on a specified token length. This adapts the content to LLM context window limits, vector database ingestion requirements, and other downstream scenarios.
Use Cases
| Scenario | Description |
|---|---|
| Knowledge Base Construction | Split long documents into vector-database-compatible segments for similarity retrieval |
| LLM Q&A | Split overly long context to prevent token limit errors that cause truncated or failed responses |
| Content Distribution | Split large content into readable short paragraphs for push notifications, summary generation, etc. |
Configuration
Input Configuration
- Input Variable — Connect to an upstream Text Extraction node and select its text output variable.
- Max Segment Length (Tokens) — Maximum token count per segment. Default is
500; adjust based on document size and downstream requirements.
Output Variables
| Variable | Type | Description |
|---|---|---|
segmentsArray | Array[String] | List of split segments |
segment_count | Number | Total number of segments |
Downstream Usage
The Document Split node outputs an array variable, which typically needs to be processed element by element using a Task Loop node.
Typical flow:
Text Extraction → Document Split → Task Loop
└─ Model Node (process one segment)
→ Merge Output NodeIn the Task Loop node, set the loop input to the segmentsArray output from the Document Split node. Nodes inside the loop body can reference the current segment via the loop variable and pass it to a Model node for translation, summarization, Q&A, or other processing. All results are aggregated into an array output.
segment_countcan be used in downstream condition nodes — for example, to take a different processing branch when the segment count exceeds a threshold.